
MATOcolori 24 Hours: A technical view
This weekend, a 24h long simracing event took place. A review from a infrastructure perspective.

Keep in mind: I cannot look into the rFactor server process and can basically just watch what the process is doing/ reporting, it's hard to identify issues, but I can tell about contexts and situations.
I'm a bit tired, expect typos and weird wording ;)
Preparation
Preparation is everything. For the event, a dedicated, non-virtualized dedicated server was ordered. The server ran on the latest Windows Server edition, 64 GB memory, i7-8700, automatic updates disabled, firewall closed.
To prevent any junk requests (especially RDP), the server was completely closed from the internet. The only accessible ports were the Ports needed by the rFactor 2 platform itself, NOT including the WebUI port (default: 5397).
The executable of the rFactor 2 will from now on only called server or server process, to keep it short.
To prevent the server process from drowning somewhere in the processors' scheduler, the server ran with a higher (not highest) priority, given from the outside via a batch script.
The need for data
Especially for identifying upcoming issues the need for data to monitor is given. For this purpose, the server was monitored using a attached module ("reciever module") using psutil, pywinauto, Flask and Munin.
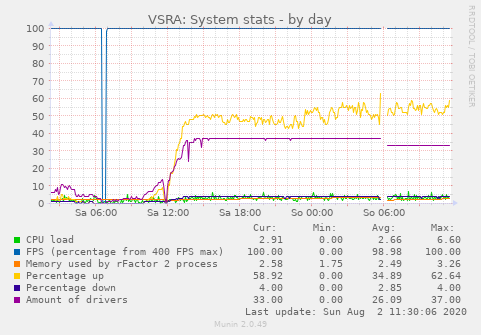
The "reciever" module allowed to get interval-based (not real-time!) data out of the server based on the process informations and infos from the UI of the server might deliver.
The need for procedures
- As every attendee to rFactor 2 events knows, the plattform has it's issues. Especially a red flag scenario required a todo-list. For this purpose, the server was extended with a plugin, creating batch files each time the leading car completes a lap. This allows to restore the order and the laps in case of a restart of the server. Link for the plugin
- In case of a red flag, the complete server will be rebooted.
- During race it was important to AVOID that connecting clients are downloading the livery and track files each time, causing the server to waste bandwith on the client. This was done especially with the lag spikes for joining clients in mind.
- Another point was the topic of failing driver swaps. Before the event we decided to force cars with a failed driver swaps into an disconnect, let them reconnect (and retry). If this succeeds, an approximation of laps will be added to the car, based on the time lost, to keep it fair as possible.
Update 21th february 2021: Get people back running
A short update what could be done with a DNF'ed car based on the setting that the server allows rejoin of drivers. As it turned /undq wipes the result state, but only if the state is DQ, but not when DNF. But with /dq and /undq, you can basically get people back running, forcing a transistion from DNF to DQ to running again.
| Situation | Action | Rejoined? |
|---|---|---|
| Race rejoin after pressing ESC and disconnect+reconnect | none | ❌ |
| Race rejoin after pressing ESC and disconnect+reconnect | /undq | ❌ |
| Race rejoin after pressing ESC and disconnect+reconnect | /dq and /undq | ✅ |
| Race rejoin after pressing ESC without leaving | /dq and /undq | ✅ |
The race
Session switch issues
During the switch from qualifying to warmup approx. 5 clients got disconnected.
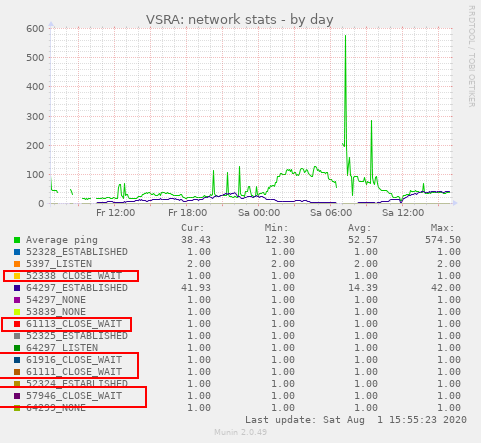
This disconnect was (probably) visible after the session switch in the monitoring, as we had the same amounts of CLOSE_WAIT connections.
According to RFC 793 (TCP), the CLOSE_WAIT defines as follows:
CLOSE-WAIT - represents waiting for a connection termination request from the local user.
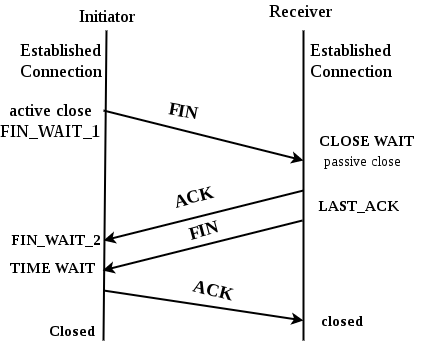
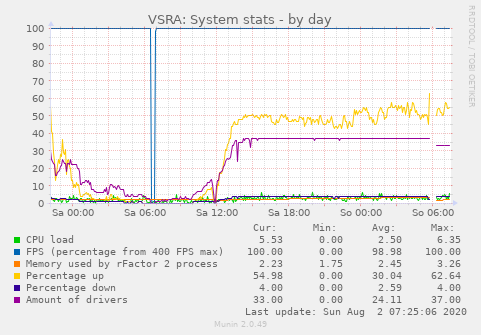
In my undestanding this means that a client informs the server to close a TCP connection (I'm unsure about the port purpose as I'm not doing reverse engineering here) but it never gets really closed as the ACK/ FIN from the server to the client is never answered with another ACK. Interestingly, the monitoring seems to confirm that conclusion as the driver count had a clear drop at the start of the event, basically the switch from qualification into warm up.
Another drop could be seen at the race start where 3 cars got an in-game DQ state, which also showed up as the smaller drop:
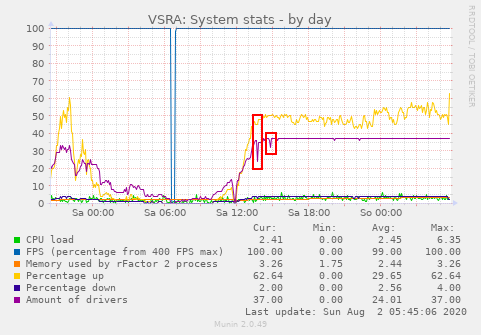
The race
I will structure the race in several blocks with the amount of noteworthy events in the title. Example for noteworthy events are
- driver swap fail
- disconnect during racing
- lag spike
- graph peak
- game crash
- pit issues
- game issues (in general)
Hour 1-4 ~ 4 events
During this period, we faced first driver swap issues and the server connections peaked to about 60, meaning that basically another grid count was present as spectator at some point.
Hour 5-9 ~ 4 events
During the hours 5 to 9, the server peaked for serveral times at about 60 connections on Port 64297.
In hour 7 a display issue was identified, causing cars being listed with the previous driver instead of the current one. But this issue was caused by data recieved from the shared memory.
After being about 10 hours on the server, the first spectator client crashed, interstingly causing a file size quite close to the maximum Int32 size (which is 2147483647). This may be affected by some settings, but a crash is still not acceptable for exceeded data.
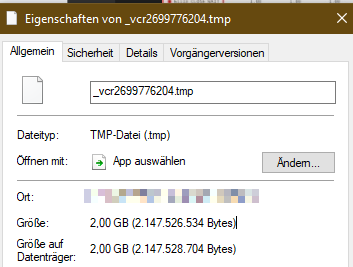

The trace log clearly shows that the process was not properly shut down, it most likely had a segmentation fault.
Hour 10-13 ~ 1 event
We handled at least one disconnect during this period.
Hour 14-17: Red flag!
After 14 1/2 hours into the session we decided to call a red flag after >= 8 clients got disconnected at once. Interstingly, the purple driver count was not affected in the monitoring, but the upstream percentage increased by about 15% BEFORE the disconnects. But keep in mind, the graphs are interval based, so the driver decrease might simply not be visible here at all.
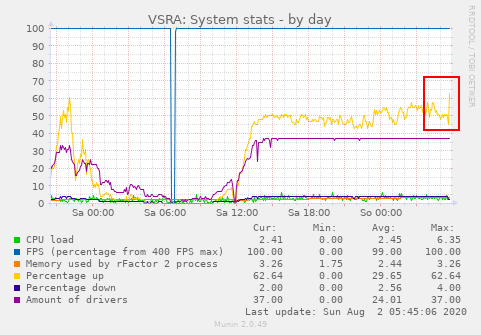
If the upstream percentage includes downloading skinpacks, some of the drivers may actively caused that peak then.
In hour 17, we also dealed with another type of driver swap fail: A car had an unclear state about which driver is in the car. The issue was resolved with a disconnect and rejoin.
Hour 18-21 ~ 6 events
During hour 18, one car had the issue that the car was pitting, but no service was done. We assume that the driver entered the pit box before the "pit crew is ready" acknowledgement.
Hour 20 showed an peak for Port 54297 (TCP) with more than 70 connections, but without any issues immediately after.
Hour 21-24 ~ 5 events
No additional things to report, dealing with driver swaps mostly.
Oddities
Bug in lap count
After the restart, we discovered a bug, causing a car to loose 4 laps after passing start/ finish during a pit stop.

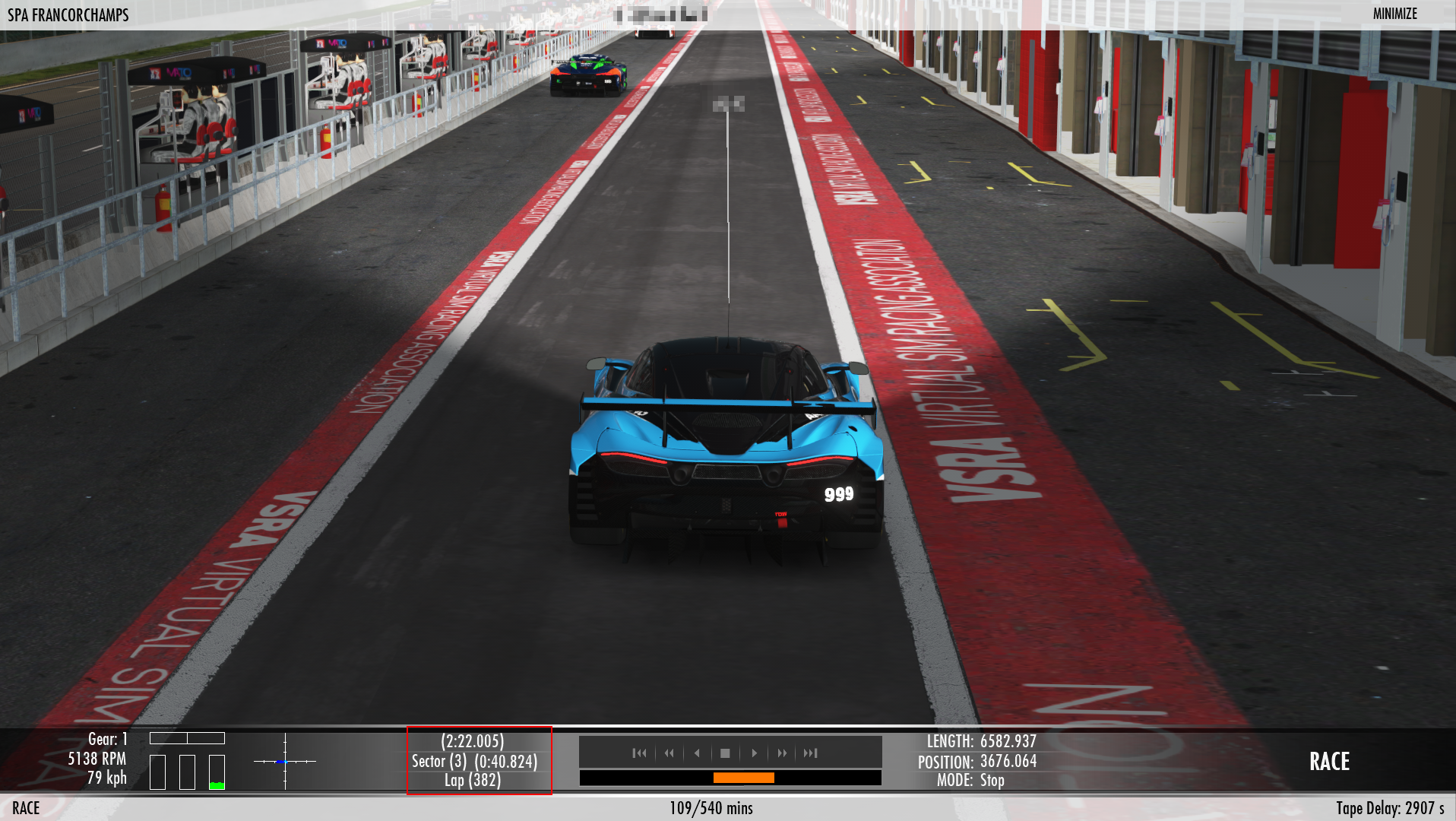
The missing laps were granted again.
Network peaks
The graph showed a connection peak of ~160 connections on the TCP 54297 port. I really doubt that this was done by the drivers. Also note the small peaks at the far right of the graph. I suspect a scanning service from the internet behind this.
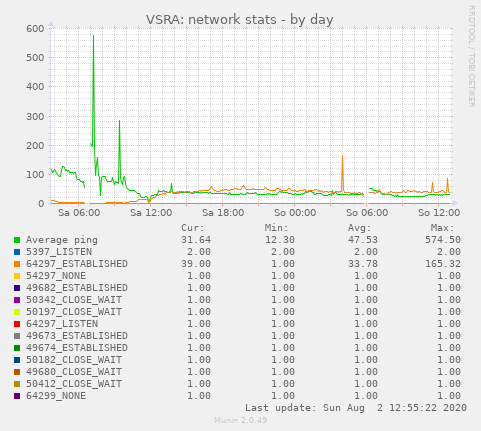
Disproportionate graphs
After the restart, several DNF'd cars did not resume racing. Interstingly, the percentage of upstream did not decrease. Spectators might affect the upstream graph aswell here.
Lack of admin features
The platform clearly lacks a possibility to either map an IP to an client/ specator or to kick specators. Den, I will find you.
Patterns
It feels like a lot of the driver swap issues are independent of the amount of spectators. It looks a bit like the car has a "faulty" slot since the start of the event. But the solution to disconnect them and let them rejoin showed that it worked in almost each case at the first try.
So here might be a bug in either the join or session swap features.
In terms of disconnects, a lot of them happened on the main straight (viewed from the replay), which was quite odd.
AI Takeover
For a fraction of a second, it was clearly visible that a car undergoes several states during a driver swap
- Driver in the car
- Driver in the car, but as AI
- New driver in the car
- Old driver spectator
That may be no new point to learn, but it helps understanding why disabling the AI takeover is important here!
Conclusions
- First of all, the server felt under control. Having uninterrupted racing for in sum 23 hours and 45 minutes is in my opinion quite an good result!
- I recieved no reports of lagging cars during the race
- The session swap is weird, from the outside it looks like clients getting disconnected and if you having a poor latency at that point, you might be loosing connection
- There was at least 1 driver swap issue per hour, which is quite worrying!
Some numbers for the friends of statistics
- Voice traffic: About 12 Gigabytes
- Number of minutes when race control was absent: 0
- Incident reports processed: 80
- Penalties given: 57
- Red flags: 1
- Total race time: 23 hours 45 minutes
- Approx. laps driven (all teams): ~ 18000
- Driver swaps done: 433 (including failed!)
- Pitstops: 570 (including driver swaps)